Bring Your Own Scores
Vathy M. Kamulete
Royal Bank of Canadavathy.kamulete@rbc.com
Last Updated: 2021-09-14
Source:vignettes/diy-score.Rmd
diy-score.RmdPlease see the arXiv paper for details. We denote the R package as dsos, to avoid confusion with D-SOS, the method.
DIY: Bring Your Own Scores
We show how easy it is to implement D-SOS for a particular notion of outlyingness. Suppose we want to test for no adverse shift based on isolation scores in the context of multivariate two-sample comparison. To do so, we need two main ingredients: a score function and a method to compute the \(p-\)value.
First, the scores are obtained using predictions from isolation forest with the isotree package (Cortes 2020). Isolation forest detects isolated points, instances that are typically out-of-distribution relative to the high-density regions of the data distribution. Naturally, any performant method for density-based out-of-distribution detection can effectively be used to achieve the same goal. Isolation forest just happens to be a convenient way to do this. The internal function outliers_no_split shows the implementation of one such score function in the dsos package.
dsos:::outliers_no_split
## function (x_train, x_test, num_trees = 500)
## {
## iso_fit <- isotree::isolation.forest(df = x_train, ntrees = num_trees)
## os_train <- predict(iso_fit, newdata = x_train)
## os_test <- predict(iso_fit, newdata = x_test)
## return(list(test = os_test, train = os_train))
## }
## <bytecode: 0x000000000a0f7898>
## <environment: namespace:dsos>Second, we estimate the empirical null distribution for the \(p-\)value via permutations. For speed, this is implemented as a sequential Monte Carlo test with the simctest package (Gandy 2009). Permutations do not require to derive the asymptotic null distribution for the test statistic. The function od_pt in the dsos package combines the scoring with the inference. The prefix od stands for outlier detection and the suffix pt, for permutations. dsos sometimes provides sample splitting and out-of-bag variants as alternatives to compute \(p-\)values. Both sample splitting and out-of-bag variants use the asymptotic null distribution for the test statistic. As a result, they can be appreciably faster than inference based on permutations. The code for od_pt is relatively straightforward.
dsos::od_pt
## function (x_train, x_test, R = 1000, num_trees = 500, sub_ratio = 1/2)
## {
## scorer <- function(x_train, x_test) {
## outliers_no_split(x_train = x_train, x_test = x_test,
## num_trees = num_trees)
## }
## result <- exchangeable_null(x_train, x_test, scorer, R = R,
## is_oob = FALSE)
## return(result)
## }
## <bytecode: 0x00000000122656f8>
## <environment: namespace:dsos>Take the iris dataset for example. When the training set only consists of Iris setosa (flower species) and the test set, only of Iris versicolor, the data is incompatible with the null of no adverse shift. In other words, we have strong evidence that the test contains a disproportionate number of outliers, if the training set is the reference distribution.
set.seed(12345)
data(iris)
x_train <- iris[1:50,1:4] # Training sample: Species == 'setosa'
x_test <- iris[51:100,1:4] # Test sample: Species == 'versicolor'
iris_test <- od_pt(x_train, x_test)
plot(iris_test)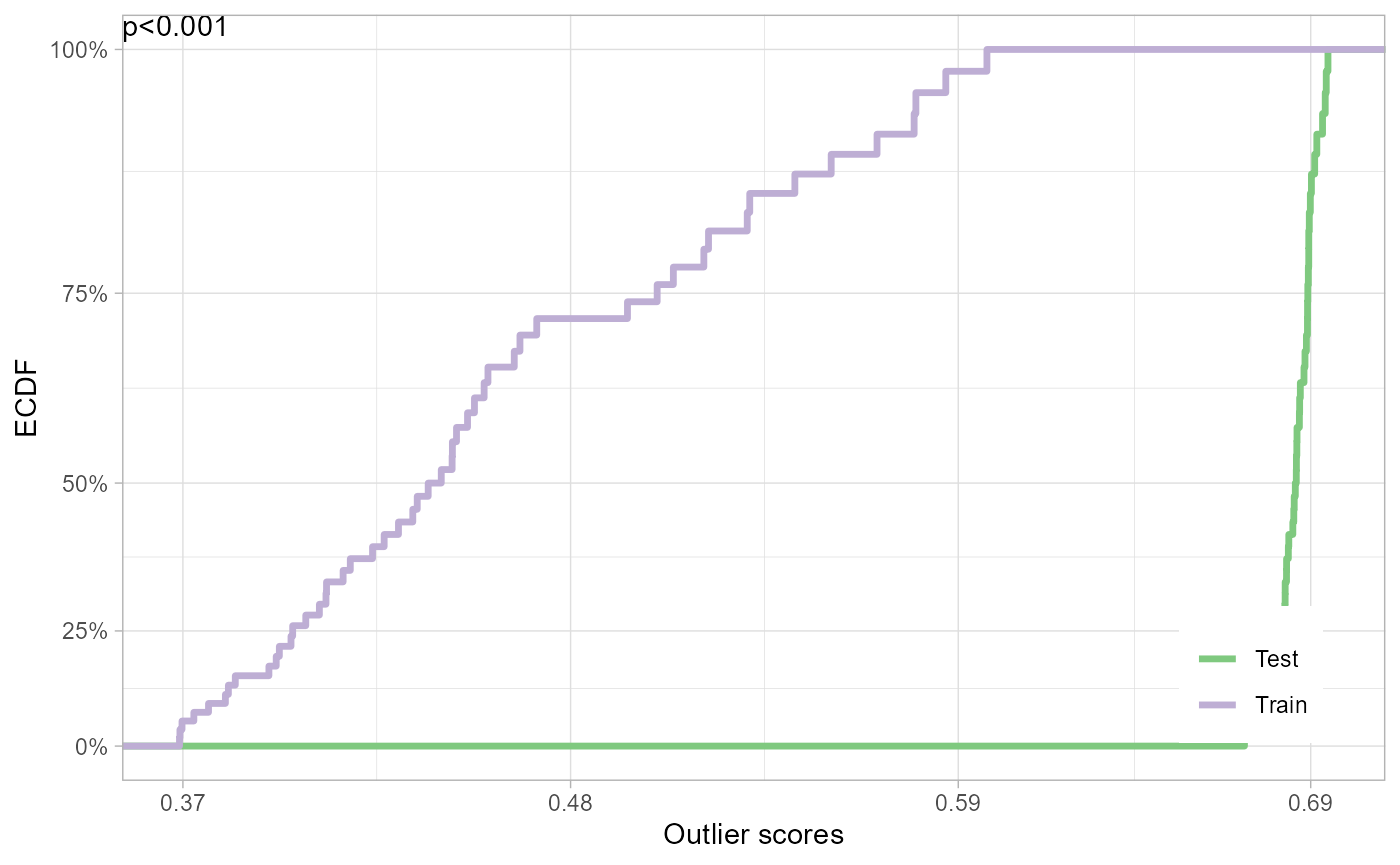
You can plug in your own scores in this framework. Those already implemented in the package can be useful but they are by means the only ones. If you favor a different method for out-of-distribution (outlier) detection, want to tune the hyperparameters, or choose a different notion of outlyingness altogether, dsos provides the building blocks to build your own. The workhorse function, powering the approach behind the scenes, is a way to calculate the the test statistic, the WAUC, from the outlier scores (see wauc_from_os).
References
Cortes, David. 2020. Isotree: Isolation-Based Outlier Detection. https://CRAN.R-project.org/package=isotree.
Gandy, Axel. 2009. “Sequential Implementation of Monte Carlo Tests with Uniformly Bounded Resampling Risk.” Journal of the American Statistical Association 104 (488): 1504–11.